Un an de Data Science en entreprise : Ce que j'ai appris
Réflexions sur ma première année en entreprise en tant que Data scientist
TL;DR
La Data science est un domaine assez vaste. Selon votre contexte, vous pouvez être appelé à jouer plusieurs rôles dans le même projet. Être autodidacte et faire de la veille technologique est donc important. Connaitre les technologies de création d’api pour servir un modèle, de conteneurisation et d’orchestration comme Docker, Kubernetes, de cloud come AWS ou GCP ou Azure sont un gros plus. Les bases de données et une bonne communication sont essentielles.
Introduction
Cela fait désormais 1 an que je travaille en tant que Data Scientist dans une startup marocaine qui fait de l’IA. Dans cet article, je vous partage mon expérience. Comment ai-je obtenu le poste? Quelle est ma formation et quelles étaient mes attentes et espérances? Qu’ai-je appris après 1 an en entreprise ? J’ai intégré Konta en Février 2019 en tant que stagiaire académique afin d’obtenir mon diplôme d’ingénieur. Plus tard en Juin 2019, l’entreprise m’a proposé un contrat professionnel pour le poste de Data Scientist que j’ai accepté. Konta est une plateforme de gestion et traitement automatique des factures qui vous débarasse des factures papiers et la lenteur du traitement humain. Au cœur de ce produit, se trouve KontaBrain, notre moteur d’intelligence artificielle responsable de l’extraction automatique des informations importantes telles que les montants et autres sur les factures.
Comment ais-je obtenu le post ?
J’ai fait des études d’ingénieur en Informatique avec le Big Data et l’intelligence artificielle comme spécialité. Mais mon intérêt pour la Data Science a commencé bien avant mes cours de spécialité. En effet, avant de débuter mon dernier semestre de spécialité, j’avais déjà une certification de Data scientist de Datacamp et avait fait un stage d’été au laboratoire de recherche de mon école. Il s’agissait d’un stage de recherche où on a participé à une compétition d’intelligence artificielle où il fallait détecter des maladies vocales à partir d’enregistrements audio de la voix des patients. Nous avons terminé 4ème de cette compétition qui aura été riche en apprentissage et exposition aux différentes étapes d’un projet de Machine Learning. C’est d’ailleurs les discussions sur cette fameuse compétition qui ont meublé la grande partie de l’entretien d’embauche. Quels algorithmes avez-vous utilisé? Comment avez-vous transformé les données ? Quelle approche avez-vous utilisé pour mesurer les performances de vos modèles? Comment avez-vous amélioré cette mesure? Tant de questions qui m’ont permis de prouver au recruteur que j’étais autodidacte, un des traits importants de tout Data Scientist.
Quelles sont mes tâches en tant que Data Scientist ?
A mon arrivé à Konta, nous formions une petite équipe de 2 Data Scientists. Très tôt, j’ai compris que mon rôle ne se résumera pas à faire des “import pandas as pd” ou “import tensorflow as tf”. Mes premières tâches consistaient à la création d’un data lake pour faciliter notre approvisionnement et gestion des données. Il m’a fallu donc revoir mes notions de Hadoop, Hive et tous les outils de cet écosystème. 1er enseignement : un data scientist peut être amené à faire des taches de data engineer. Après cette étape, j’ai vite commencé à travailler sur notre moteur KontaBrain qui utilise plusieurs algorithmes de computer vision et de natural language processing. Bien que je prenais plaisir à entraîner des modèles de Deep Learning, les améliorations de performances venaient surtout d’une meilleure connaissance des données et de leur traitement. C’est cette remarque qui m’a d’ailleurs amené à écrire ceci sur linkedin :
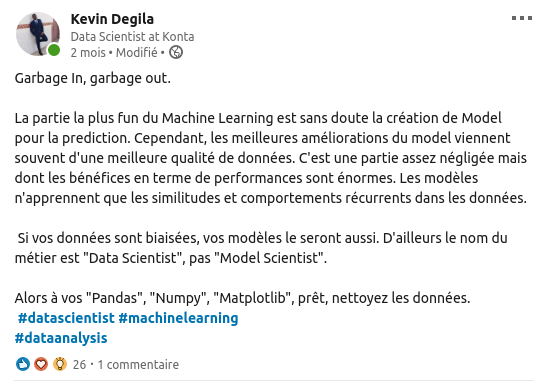
On ne livre pas au client des modèles qui sont dans des jupyter notebooks. Il faut pouvoir servir ces modèles à travers un api. Cette étape m’a permis d’améliorer mes compétences en Flask qui est un framework léger de création d’application web en Python. Avec les compétences acquises désormais, je fais toujours en sorte de servir mes modèles entraînés pour les projets personnels comme SmartBin .
Servir son modèle, c’est bien, mais cela ne sert à rien si c’est sur votre pc et que vous êtes le seul à en avoir accès. Cette problématique m’a exposé aux technologies comme Docker pour la conteneurisation, docker compose et Kubernetes pour la mise à échelle. Entre l’acquisition de ces compétences, j’ai été exposé également au technologies du Cloud sur Google Cloud Platform.
Une partie assez négligée quand on est encore apprenant, mais très importante est la connaissance des bases de données, une base de donnée relationnelle sql et une nosql de préférence. Ceux-ci s’avèrent très utiles quand il faut sauvegarder les résultats de ses modèles pour un monitoring de performance.
Pour finir, la communication effective est l’une des choses que j’ai apprise et que je continue d’apprendre. Que ce soit une communication technique avec des visualisations qui illustre clairement les informations voulues ou communication simple entre collègues pour une bonne collaboration.
Que faut-il retenir ?
Ce qu’il faut retenir, c’est que pour satisfaire les exigences de la data science en entreprise, il faut rester autodidacte et curieux. On est dans un domaine qui évolue très vite. Faire de la veille technologique devient indispensable.
Les technologies citées sont relatives à mon contexte, mais peuvent se généraliser facilement. Il faut noter également que si j’ai été exposé à autant de technologies, c’est dû à la taille relativement petite de notre équipe, mais surtout à un environnement qui favorise l’apprentissage.
Partage de mon expérience
Cet article est l’un de ceux que j’aurais aimé lire pendant que j’étudiais encore à l’école. Malheureusement, la partie francophone de la data science ne fournit pas encore assez de ressources du genre. Ce blog est un effort pour changer cela. Je partage également mes compétences à travers ma chaîne Youtube
à laquelle je vous encourage à vous abonner.
