Créer une application de Machine learning avec Tensorflow 2.0 et Flask et la déployer sur Google Cloud
SmartBin : Recyclable ou Organique#
SmartBin est le nom de notre projet. Il s’agit d’une application qui utilise l’intelligence artificielle pour classer les objets comme recyclable ou organique. L’utilisateur soumet une image de son objet et l’application lui dit si son objet est recyclable. A long terme, le modèle crée peut être intégré dans une poubelle équipée d’un caméra et d’une alarme. A chaque fois que vous y mettrez un objet non recyclable, vous aurez un signalement, qui vous indique la poubelle dédiée à ce genre d’objet. C’est notre manière de participer au défi environnemental de notre époque. Sans plus tarder, créons SmartBin.
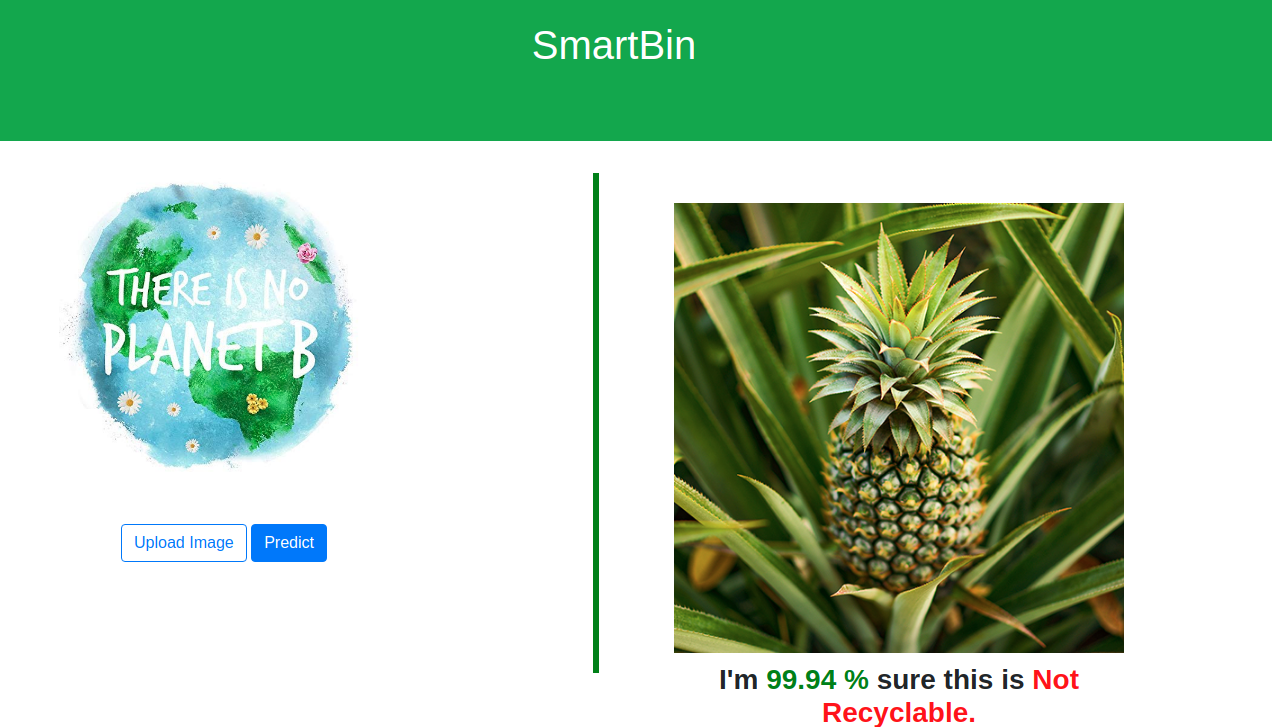
Plan de notre projet#
- Télécharger le dataset
- Entraîner un réseau de neurones convolutionnels avec Tensorflow 2.0/Keras
- Créer une application Flask pour servir notre modèle
- Déployer le modèle sur Google App Engine.
Télécharger le Dataset#
Le dataset utilisé dans ce projet nous vient de Kaggle . C’est souvent le premier site que je consulte quand je cherche un dataset sur un sujet intéressant. Le dataset contient 22564 images d’entrainement et 2513 images de Test classé en “Recyclable” ou “Organique”. Il suffit d’avoir un compte Kaggle pour télécharger ces images.
Entraîner un réseau de neurones convolutionnels avec Tensorflow 2.0#

Ici, nous entraînerons de la manière la plus simple possible notre modèle avec l’interface Keras de Tensorflow 2.0. Nous nous concentrons sur le fait d’avoir un premier modèle performant sans vouloir le parfaire. Pour cela nous utilisons une simple architecture de CNN avec un “ModelChekpoint” qui nous permettra de sauvegarder le modèle le plus performant sur les données de test durant l’entrainement. Une fois le modèle déployé, nous pouvons l’améliorer lors de versions futures de notre application.
Importer tensorflow.keras#
Si vous n’avez pas encore la dernière version de tensorflow, il vous suffit de le faire avec pip:
pip install tensorflow
Nous pouvons maintenant importer les modules de tf.keras dont on aura besoin:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Flatten
from tensorflow.keras import optimizers
from tensorflow.keras.callbacks import ModelCheckpoint
Importer les images#
Pour importer les images, nous utiliserons le générateur d’image de tensorflow. Mais avant, il faut définir le chemin des dossiers d’images d’entrainement et de test:
train_dir = 'data/TRAIN/'
test_dir = 'data/TEST/'
Nous pouvons désormais créer nos générateurs d’images avec le module ImageDataGenerator. Plus de détails sur ce module dans de futurs articles. Pour le moment, vous noterez qu’on normalise les images pour que les valeurs de pixels soient entre 0 et 1 avec le paramètre “rescale”. Notre réseau de neurones attendra des images de même taille. Nous les ajusterons tous pour qu’elles aient une hauteur et largeur de 150.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# All images will be rescaled by 1./255
train_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,
# All images will be resized to 150x150
target_size=(150, 150),
batch_size=32,
class_mode='binary')
test_generator = test_datagen.flow_from_directory(
test_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
Définir l’architecture de notre réseau de neurones et le compiler#
Nous pouvons maintenant définir l’architecture. Nous optons ici pour un simple [CONV => RELU => POOL] *4.
from tensorflow.keras import layers
from tensorflow.keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
Une fois l’architecture définie, on compile le modèle.
model.compile(loss='binary_crossentropy',
optimizer=RMSprop(lr=1e-4),
metrics=['acc'])
Définir le callback ModelCheckpoint et entraîner le modèle#
Un callback est une fonction qui est exécutée après chaque itération lors de l’entrainement. Ici on souhaite sauvegarder le meilleur modèle à chaque itération. Nous entraînerons et testons notre modèle pour 50 itérations.
checkpoint = ModelCheckpoint(filepath='./best_model.h5', monitor="val_acc", mode="max",
save_best_only=True, verbose=1)
callbacks = [checkpoint]
# Training and Validation
history = model.fit_generator(
train_generator,
steps_per_epoch=int(22564/32),
epochs=50,
validation_data=test_generator,
validation_steps=int(2513/32),
callbacks=callbacks)
Après 27 itérations, nous avons une précision de 90% sur les images de test, ce qui nous convient parfaitement pour la première version de notre modèle. Grâce au ModelCheckpoint, nous pouvons arrêter l’entrainement car le le fichier best_model.h5 contient déjà notre meilleur modèle. C’est l’un des avantages de ce callback. C’est désormais le moment de créer une application pour servir ce modèle.
Créer une application Flask pour servir notre modèle#
Pourquoi Flask ? Parce que ce framework est simple, léger et facile à apprendre. On est data scientist et pas développeur Web. Tenez, voici tout le code nécessaire pour créer un simple site qui affiche “Hello world” avec Flask.
from flask import Flask
app = Flask(__name__)
@app.route("/")
def hello():
return "<p>Hello World!</p>"
Cet article n’est pas un tutoriel de Flask donc nous ne rentrerons pas en détails sur chaque composons. Nous dirons simplement ce que fait chaque bout de code.
Structure de notre application#
- static : contient les fichiers statiques de notre application. Le sous-dossier static/models contient notre meilleur modèle. le dossier static/uploads contiendra les images que nos utilisateurs soumettrons à l’application. Nous pouvons récuperer ces images plus tard pour améliorer le modèle.
- templates : contient le fichier index.html de notre application. Flask est configuré pour chercher dans ce dossier les fichiers html que nous retournons.
- main.py : Cest le backend de notre projet. Tout se fait dans ce fichier. son exécution lance le serveur. C’est le code dans ce fichier qui nous interesse le plus.
Création de main.py#
En une phrase, voici ce que fait main.py . Il charge notre modèle, récupère les images soumises par l’utilisateur en les normalisant et leur donnant la taille qu’attend le modèle, fait la prédiction et renvoie à index.html la classe de l’image et la précision.
Commençons par installer Flask.
pip install flask
Nous pouvons maintenant ouvrir main.py et importer Flask avec les modules de Tensorflow qu’on utilisera.
from flask import Flask, render_template, request, send_from_directory
from tensorflow.keras.preprocessing import image
from tensorflow.keras.models import load_model
Chargeons le modèle crée avec la fonction load__model(). Cette fonction devra s’exécuter qu’une seule fois et ce avant la première requête. Nous ajouterons donc le décorateur @app.before_first_request et rendrons la variable model global pour qu’elle reste disponible même en dehors de la fonction.
@app.before_first_request
def load__model():
"""
Load model
:return: model (global variable)
"""
print('[INFO] Model Loading ........')
global model
model = load_model(MODEL_FOLDER + 'best_model.h5')
print('[INFO] : Model loaded')
Écrivons maintenant la fonction qui utilise ce modèle pour faire la prédiction sur une image:
def predict(fullpath):
data = image.load_img(fullpath, target_size=(150, 150, 3))
# (150,150,3) ==> (1,150,150,3)
data = np.expand_dims(data, axis=0)
# Scaling
data = data.astype('float') / 255
# Prediction
result = model.predict(data)
return result
Nous pouvons désormais écrire la fonction qui reçoit les requêtes de type POST , récupère l’image soumise, la sauvegarde, fait la prédiction et retourne la classe et la précision.
@app.route('/', methods=['POST', 'GET'])
def index():
if request.method == 'POST':
file = request.files['image']
fullname = os.path.join(UPLOAD_FOLDER, file.filename)
file.save(fullname)
result = predict(fullname)
pred_prob = result.item()
if pred_prob > .5:
label = 'Recyclable'
accuracy = round(pred_prob * 100, 2)
else:
label = 'Organic'
accuracy = round((1 - pred_prob) * 100, 2)
return render_template('index.html', image_file_name=file.filename, label=label, accuracy=accuracy,
predict=True)
else:
return render_template('index.html', predict=False)
Un point sur render_template. Ce module nous permet d’afficher la page html par défaut dès qu’un utilisateur nous envoie une requête de type GET. Dans le cas d’une requête POST , il nous permet de renvoyer au fichier html les variables image_file_name, label, accuracy et predict. Il s’agit là de variable python qu’on peut utiliser dans le code html en les mettant dans des doubles accolades comme ceci par exemple pour la variable label : {{ label }}. C’est rendu possible par le moteur de template Jinja qui permet également entre autres de mettre des conditions dans le fichier html. Vous remarquerez que la variable predict nous permet de contrôler l’affichage des résultats de la prédiction.
Pour lancer le serveur, il nous suffit d’exécuter le fichier main.py. Cela est rendu possible par le dernier bout de code du fichier:
if __name__ == '__main__':
app.run(host="0.0.0.0", port=8080, debug=False)
Notre application sera ainsi disponible au port 8080. Cette partie conclut la création de notre application. Je n’ai pas décrit le fichier index.html pour ne pas rendre cet article trop long, mais il est assez compréhensible une fois que le fichier main.py est compris. Allez!! Déployons cette application sur Google Cloud pour le rendre disponible à tout le monde.
Déployer le modèle sur Google App Engine#
Pourquoi Google App Engine ? Parce qu’il permet de déploiement rapide en créant une image docker de notre projet. 2 ou 3 commandes et le modèle est disponible pour tous. On a donc pas à se soucier de la création d’un serveur et de ses configurations de sécurité, Google s’en charge. De plus, après la création d’un compte Google Cloud, vous avez accès à 300 euros de crédits gratuits pendant 1 an, ce qui permet de faire plusieurs expérimentations sans dépenser. Revenons à notre application pour la déployer sur App Engine, il nous faut créer le fichier app.yaml.
YAML est un langage de sérialisation utilisé par de nombreux frameworks pour configurer et stocker paramètres de programme. Le fichier «app.yaml» contient les paramètres de configuration tels que l’environnement App Engine que nous souhaitons utiliser (dans notre cas, l’environnement flex qui paramétrable est préférable à l’environnement standard), la version de python à utiliser, le nom du script python à exécuter (ici main.py) et les informations spécifiques au hardware nécessaire.
En production, nous utiliserons le serveur gunicorn au lieu de celui de Flask. Ceci pour des raisons de sécurité et de stabilité.
Contenu de app.yaml:
runtime: python
env: flex
entrypoint: gunicorn -b :$PORT main:app
runtime_config:
python_version: 3
manual_scaling:
instances: 1
resources:
cpu: 1
memory_gb: 0.5
disk_size_gb: 10
Tout est désormais fin prêt pour le déploiement. Je suppose qu’à cette étape, nous avons déjà crée notre compte Google Cloud. La prochaine étape est de créer un projet en cliquant sur le bouton à coté de Google Cloud Platform dans le coin supérieur gauche, puis sur Nouveau Projet comme l’indique les images suivantes.
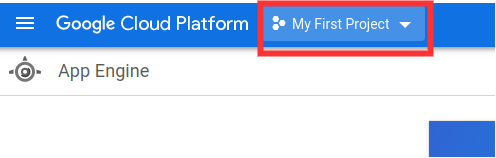
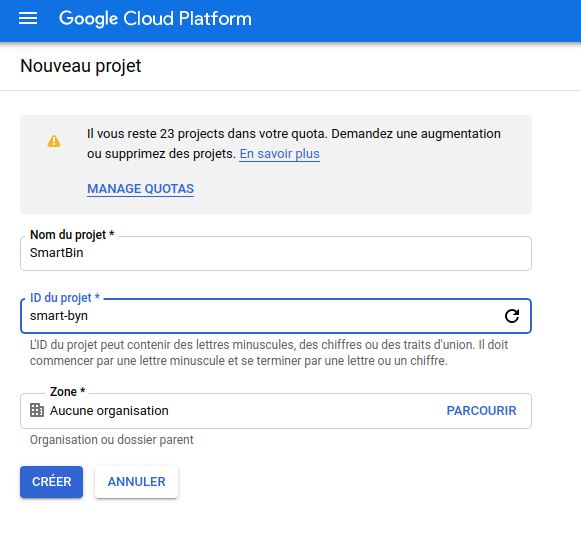
Une fois, le projet crée, cliquez sur le Menu à gauche, puis sur App Engine. Dans le coin supérieur droit, Cliquez sur le premier bouton pour accéder à la console qui s’affichera en bas de la page:
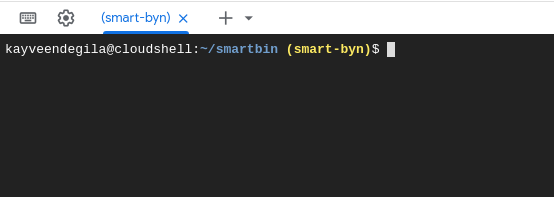
Nous allons ici, déplacer les fichiers de notre application vers le cloud. Il s’agit ici de tous les fichiers et dossiers sauf ceux dans le dossier ModelTraining ayant servi à l’entrainement. On compresse le tout dans un fichier app.zip qu’on va ajouter à notre machine sur le cloud. Pour ce faire, cliquez sur les 3 points dans le coin gauche de la console puis sur Importer un fichier et choisir le fichier app.zip.
Une fois le fichier app.zip chargé, nous allons créer un dossier SmartBin, déplacer le fichier compressé dans ce dossier puis le décompresser avec les commandes suivantes:
mkdir smartbin
cd smartbin
mv ../app.zip app.zip
unzip app.zip
Nous avons désormais, notre application sur le cloud. Encore une dernière étape et nous pourrons déployer .
Nous devons recréer notre environnement local en installant les packages nécéssaires. Cela est fait avec la création d’un dossier lib et l’installation dans ce dossier de tous les packages dans notre fichiers requirements.txt.
mkdir lib
pip install -t lib -r requirements.txt
Tout est prêt! Le déploiement se fait en une ligne de commande:
gcloud app deploy app.yaml
Lors de l’exécution de cette commande, on vous demandera la localisation à laquelle vous souhaitez que votre application soit hébergée, celle la plus proche de votre pays étant la meilleure en terme de rapidité. Après, un simple affichage de quelques configurations demande votre validation. Après votre “OK”, une image docker est crée et déployée. L’application est désormais disponible pour tous les utilisateurs à travers le monde. Pour obtenir son url il suffit d’exécuter la commande suivante:
gcloud app browse
Voilà Smartbin est désormais disponible pour tous à l’adresse: https://smart-byn.appspot.com/ . Si le lien ne marche plus, c’est probablement parce que j’ai supprimé le déploiement. Ca coute de l’argent d’avoir une application déployée sur App Engine.
N’hésitez pas à l’essayer et m’envoyer vos retours. Nous avons déployé un modèle très simple. Il fera probablement quelques erreurs que nous améliorons plus facilement maintenant que tout notre pipeline est en place.
Recapitulatif#
Dans ce article, nous avons:
- Entraîné un modèle de machine learning avec Tensorflow 2.0 qui classifie les images comme contenat des objets recyclable ou Non
- Créé une application Flask qui permet de servir ce modèle
- Déployé notre application sur Google App Engine
Code github de ce projet: https://github.com/kevindegila/SmartBin
Application : https://smart-byn.appspot.com
Plusieurs améliorations peuvent être apportées à la méthodologie de création mais le but ici était d’avoir une première application qui marche.