La validation croisée en Machine Learning Expliquée
La validation croisée en Machine Learning: Tout ce qu’il faut savoir.
Evaluer la performance de son modèle est une étape importante de tout projet de Machine Learning. Il faut pouvoir mesurer la capacité de généralisation de son modèle sans introduire de biais, ni fuites de données. Il est commun de diviser son dataset en données d’entrainement, de validation et de test. Malheureusement, l’on ne peut se permettre ce luxe dans les cas de projets avec peu de données. Réserver une partie du dataset pour la validation reviendrait à réduire la quantité déjà faible de données dont on dispose. Et même si on faisait ce sacrifice, les données de validation seraient trop peu pour être représentatif de l’ensemble du dataset.
Dans cet article, je présente la validation croisée ou cross-validation, qui est une méthode d’évaluation qui permet de palier aux problèmes cités ci-dessus. Le reste de cet article suivra le plan ci-après:
- Qu’est-ce-que la validation croisée
- Quels sont ses avantages et inconvenients
- la validation croisée en python avec scikit-learn
- Les types de validation croisée
A la fin de cette lecture, vous comprendrez la méthode de validation croisée, sa pertinence et les cas dans lesquels vous voudrez l’utiliser tout en étant averti de ses inconvénients. Vous pourrez l’utiliser dans vos codes avec scikit-learn pour plus de rapidité. Vous connaîtrez également les types de validation croisée et leur utilité.
Si tout cela, vous intéresse, continuez la lecture de cet article et n’oubliez pas de vous abonnez pour davantage d’articles sur la data science, l’intelligence artificielle et Python.
Qu’est ce que la validation croisée ?#
La validation croisée (ou cross-validation en anglais) est une méthode statistique qui permet d’évaluer la capacité de généralisation d’un modèle. Il s’agit d’une méthode qui est plus stable et fiable que celle d’évaluer la performance sur des données réservées pour cette tache (Hold-out Validation). Généralement lorsqu’on parle de cross-validation (cv), l’on réfère à sa variante la plus populaire qu’est le k-fold cross-validation. Dans ce cas, nous profitons de toutes les données à disposition en les divisant en k parties égales (folds) sur lesquelles on entraîne et teste un modèle pendant k itérations. A chaque itération, le modèle est entrainé sur k-1 folds et est testé sur le fold restant. Si tout ceci reste un peu flou pour vous, la figure suivante peut aider :
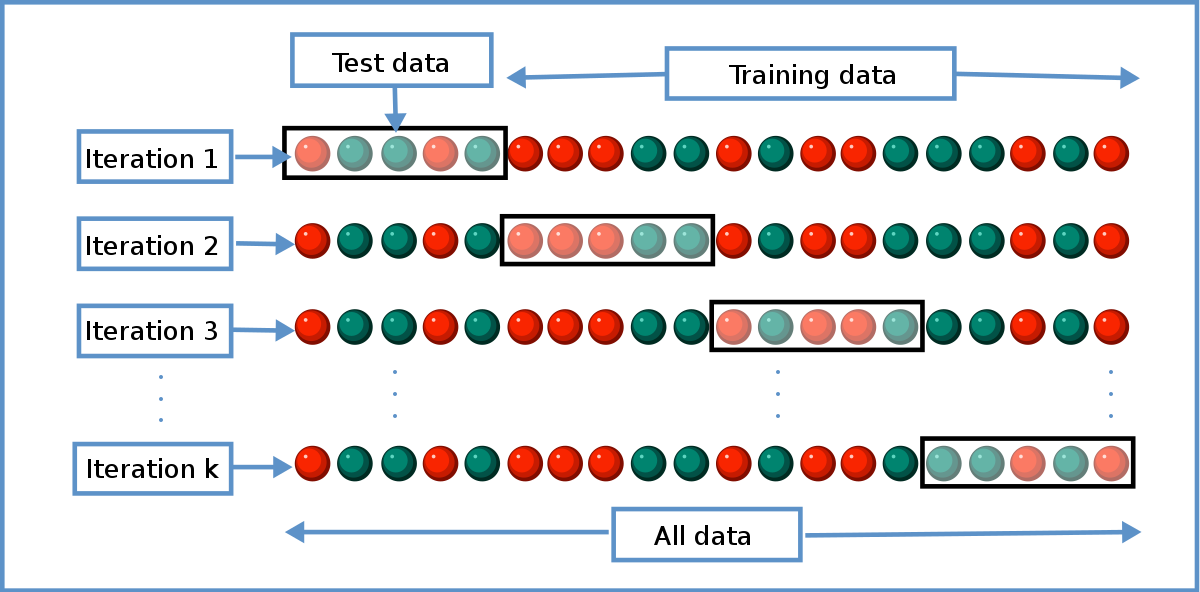
Sur cette figure, on peut remarquer que le dataset ayant 20 points a été divisé en 4 folds, chaque fold contenant 5 points ou observations. Lors de la première itération, le premier fold sert de données de Test, pendant qu’un modèle est entrainé sur le reste des folds. A la seconde itération, le modèle est de nouveau entrainé, mais cette fois-ci, sur les données des folds 1, 3 et 4, le second fold servant de données de Test, et ainsi de suite … Avec cette méthode, on s’assure que chaque point de notre dataset a servi une fois au moins au Test et à l’entrainement, tout en respectant le principe selon lequel on ne fait pas de Test que des données qui ont servi à l’entrainement (On souhaite évaluer le degré de généralisation, donc performance sur données jamais vu). Avec la validation croisée, nous aurons dans l’exemple de la figure 1, quatre valeurs de performances sur différentes données de Test, ce qui nous donne une idée approximative de l’intervalle de la performance de notre modèle, une fois qu’il sera soumis à des données qui lui sont inconnues. Mais comme toute bonne chose, la validation croisée a des avantages et des inconvénients.
Avantages et Inconvenients de la validation croisée#
Comme cité ci-dessus, le plus gros avantage de la validation croisée est l’utilisation totale de nos données. En choisissant un k=10, nous pouvons entraîner notre modèle sur 90% des données contrairement au hold-out validation qui suggère d’utiliser 75% des données pour l’entrainement. De plus, avec cette méthode, nous pouvons avoir une idée claire de la sensibilité de notre modèle aux données qui ont servi à l’entrainer. Si sur mes 4 folds, j’ai comme précision dans l’ordre, les valeurs suivantes : 98%, 68%, 16% et 96%, alors la performance du modèle dépend beaucoup du dataset d’entrainement et il me faudra faire davantage d’investigations ou changer de modèle.
Supposons maintenant que nous avions opté simplement pour un hold-out validation et que par chance, le premier fold était nos données de Test. Nous aurions comme performance 98%, pensant que nous avions un très bon modèle alors que ce n’est pas le cas. Inversement, si le 3ème fold était nos données uniques de Test, nous aurions eu une performance de 16%, pensant avoir entraîné un très mauvais modèle alors ce n’est pas le cas.
Parlons maintenant des inconvénients de la validation croisée. Comme vous pouvez l’imaginer, c’est un processus très lent et coûteux. Dans le cas d’un 10-fold cross-validation, nous entraînerons 10 fois notre modèle alors qu’on l’aurait fait qu’une fois lors d’un hold-out validation. Et plus vous avez de données, plus le processus sera encore lent.
Maintenant que nous avons vu en théorie en quoi consiste la validation croisée, passons au code pour voir comment l’utiliser dans nos projets.
La validation croisée avec Scikit-learn#
Au lieu d’implémenter l’algorithme de la validation croisée, nous même, nous pouvons simplement utiliser sklearn, la libraire de Machine learning en Python. Soit X notre matrice de “features” ou attributs ou caractéristiques, et y notre vecteur de labels dans un problème de classification. Nous souhaitons utiliser une machine à vecteurs de support (SVM) pour modéliser la relation entre X et y, puis valider notre modèle avec une validation croisée.
from sklearn.model_selection import cross_val_score
from sklearn.svm import SVC
X = features
y = labels
classifier = SVC()
scores = cross_val_score(classifier, X, y, cv=5)
print("Cross-validation scores: {}".format(scores))
Sortie :
Cross-validation scores: [ 0.98 0.957 1. 0.933 0.9 ]
A la première ligne de ce code, nous avons importer la fonction cross_val_score du module model_selection de sklearn. L’algorithme de validation croisée est déjà implémentée dans cette fonction. A la seconde ligne, nous avons importé la classe SVC qui permet d’entrainer un svm pour la classification. Les 2 lignes suivantes permettent de définir X et y auxquelles j’ai assigné les variables features et labels pour rendre ce code simple. J’aurais pu charger un dataset à cette étape et la transformer de manière à extraire X et y, mais cela rendrait le code trop long. A la ligne suivante, nous avons construit une instance de la classe SVC, qu’on a appelé classifier. Ce “classifier” est notre modèle. C’est à la ligne qui suit que tout se passe. La validation croisée en une ligne de code en utilisant la fonction cross_val_score qui retourne une liste des précisions obtenues à chaque itération. Cette fonction a pour paramètre le modèle à utiliser (dans notre cas, classifier), les features (X), les labels (y) et le paramètre cv qui permet de définir en combien de parties (folds), on souhaite diviser notre dataset. Par défaut cv = 3, mais ici on l’a mis à 5. On a donc une liste de 5 valeurs qu’on affiche à la ligne d’après.
Nous venons ainsi de voir comment utiliser un k-fold cross-validation. Mais il existe bien d’autres variantes à découvrir, et qu’il faut absolument savoir.
Les types de validation croisée#
Stratified Cross-Validation (SCV)#
Prenons un exemple simple. Le vecteur y qui represente les labels dans un projet de Machine learning est comme suit : y = [0,0,0,1,1,1,2,2,2]. Il s’agit d’un problème de classification avec 3 classes. Malheureusement, les données de chaque classe sont alignées. Et donc, si on faisait un 3-fold cross-validation, notre modèle s’entraînera uniquement sur 2 classes et sera testé sur des données d’une classe qu’elle n’a jamais vu. On a là un gros risque de mauvaise performance qui est dû à la disposition de nos données. Nous souhaitons que chaque classe soit représenté dans chaque partie ou fold lors d’une validation croisée. C’est pour cela qu’on opte pour un SCV dans ce cas. Avec un SCV, on aura donc les folds suivants : [0,1,2] [0,1,2] [0,1,2] au lieu de [0,0,0] [1,1,1] [2,2,2] lors d’un simple 3-fold cross-validation.
L’implémentation de cette variante en python avec sklearn est assez simple. Elle se fait de la même manière qu’un kfold cross-validation. Tout ce qui change est la valeur donnée au paramètre cv de la fonction cross_val_score. Au lieu de lui donner la valeur 3 par exemple, nous lui affecterons une instance de la classe StratifiedKFold du module model_selection de sklearn comme ceci:
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import cross_val_score
from sklearn.svm import SVC
X = features
y = labels
classifier = SVC()
skf = StratifiedKFold(n_splits=3)
scores = cross_val_score(classifier, X, y, cv=skf)
print("Cross-validation scores: {}".format(scores))
Nous avons choisi le nombre de folds en affectant la valeur 3 au paramètre n_splits lors de la creation de l’instance skf, puis, nous avons passé l’instance comme valeur à cv.
Leave-one-out cross-validation#
Et si nous choisissons de diviser notre dataset en parties contenant uniquement un seul point. Autrement dit, nous ferons le test de notre modèle sur une seule observation à chaque itération. Cela signifie que si dans votre dataset, vous avez 100 observations, vous entrainerez et testerez votre modèle pour 100 itérations. On peut implémenter cette variante en simplement passant le nombre d’observations ou de points du dataset au paramètre cv de cross_val_score comme ceci :
scores = cross_val_score(classifier, X, y, cv=len(X)
Nous pouvons également le faire en utilisons une instance de la classe LeaveOneOut comme ceci :
from sklearn.model_selection import LeaveOneOut
from sklearn.model_selection import cross_val_score
from sklearn.svm import SVC
X = features
y = labels
classifier = SVC()
loo = LeaveOneOut()
scores = cross_val_score(classifier, X, y, cv=loo)
print("Cross-validation scores: {}".format(scores))
Il est préférable de n’utiliser cette variante dans les cas où on a pas assez de données. Dans les autres cas, le processus serait simplement trop long et les résultats peu fiables. Il existe d’autres variantes, mais nous avons ceux qu’il faut savoir en tant que débutant dans le machine learning. Si connaitre les autres variantes vous intéresse, vous pouvez les consultez dans la documentation de sklearn ici.
Recapitulatif#
Dans cet article, nous avons présenté la validation croisée comme méthode alternative au hold-out validation. Nous avons cité également ces avantages et inconvénients. Nous avons fini par une revue de quelques variantes du kfold cross-validation que sont le Stratified Cross-validation et le leave-one out cross-validation tout en précisant les situations dans lesquelles elles sont pertinentes. Si ce sujet vous a interessé et que vous souhaitez lire davantage sur l’évaluation de vos modèles, je vous recommande le livre “Introduction to Machine Learning” coécrit par l’un des mainteneurs de Scikit-Learn.