Underfitting and Overfitting Explained Newbie
When i started learning Machine Learning, there were a lof of concepts i didn’t understand. One of them was Underfitting vs Overfitting. I didn’t have any clue about what those words mean. Now that i do understand the concept, i’m going to explain it in the simplest way possible to the old me in this article.
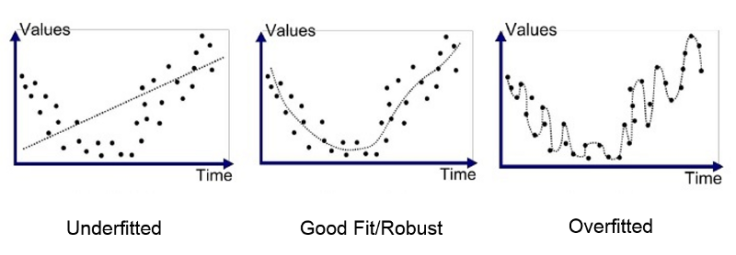
A Little Story#
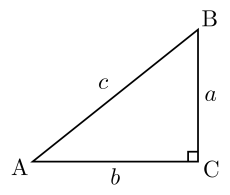
Let’s say you’re in a math class and today we’re going to learn the Pythagorian Theorem aka how to compute the length of the hypotenuse of a right triangle knowing the lenght of the two other sides. « You said it was going to be a simple explanation? Why are you bringing Math into this? » Well, bear with me, i’m sure this level of math is simple for you.
Back to our Math class, instead of just telling you what the theorem is, the teacher want you to find the right equation yourself using some data. The data contains the lengths of the 3 sides of 8 differents right triangles. c is the hypothenuse and you’re expected to find a way to compute the value of c knowing a and b. Here is the data:
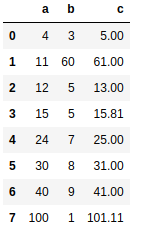
You’re going to take a test after 30 min. You’ll be given values for a and b and predict the right value for c.
The student with the most right answers can stay at home for the next week. Sounds cool right ? I mean, you will be at home watching all your favorite movies while your classmates would be in class. I don’t know about you but Peter is really excited about the challenge. He’s very lazy and doesn’t like to come to school anyway. To assure himself the first place for this challenge, he memorized all the data, all the differents values for a and b and their corresponding value for c. Don’t judge. When it comes to winning an opportunity to be lazy without consequences, Peter is not lazy anymore. He told himself that if the values for a and b in the test were like the ones in the data they were given, he would have a strong chance winning.
Paul, a passionate student find this challenge very exciting, not because of the opportunity to stay at home. He just likes to show his classmates how smart he is. He started writing down some equations and test them to find if they were the right one. So far the equation which is giving results not far from the actual values for c is this one : c = a + b. He was trying to improve when the teacher said « Time’s up ». It’s now time to see how well they can predict c for this new values of a and b:
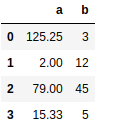
Unfortunately for Peter, none of the values is like what they had in the training data. He got a 0%. He’s very disappointed but hey Peter, How could you imagine that the data given to you to build a model will be the same in the test.
Paul also got a 0% and was disapointed too. His results were not that far from the actual values and he thinks that with enough time he could have find that c² = a² + b²
Overfitting#
This was a fictional example but it serves our goal of explaining the concept easily. What Peter did is what we call overfitting. He overfitted the data. He learned all the instances in the data so well that he performed badly on instances he newer saw. His results relies too much on the training data. It’s the same for machine learning models. When our model performs really well on the training data and badly on the test data, it’s likely overfitting. The model fails to generalize and will give us differents results on the test set if given different training data. We say that the model has a high variance.
Underfitting#
Paul’s approach was good. He was trying to find an equation so he could perform well on the test. Unfortunately his equation or model was to simple and was not even capable to predict the right values for c in the training data. Thus, he also got bad results on the test set. What Paul did is what we call underfitting. When a model have bad performance on both the training set and the test set, it’s likely underfitiing the data. Paul’s model didn’t rely too much on the training data. Given another instances he would have found the same results on the test set. We say that his model have a high bias.
Summary#
To summarize, Overfitting is when a model performs really well on a training data but badly on the test set. Underfitting is when the model performs badly on both the training set and the test set. There is more to say about this concepts. For example, if in the training data, there were over a million instances, it would have been very difficult for Peter to memorize it, so feeding our model more data can prevent overfitting. With a more complex model, Paul would have gotten good results, so choosing a more complex model can prevent underfitting.
In this example, Peter and Paul didn’t have the test set when training so they couldn’t have know if they were overfitting or underfitting. In that situation, we use a technique called cross-validation. We won’t discuss it in this article but in a next one with an end-to-end machine learning project with examples of overfitting, underfitting, cross-validation and other techniques.